Overview
The next chapter in the story of information governance and eDiscovery is quickly being written. “Visual Classification Technology” is already disrupting the way eDiscovery and data management is done today. Verity Group proudly offers this new and revolutionary technology to its clients. Visual Classification Technology automates the collection, classification and governance of documents in any file structure, format or type.
Visual Classification Technology is enormously useful when processing documents involved in litigation, regulatory/compliance proceedings, contract, record management and M&A procedures, among others.
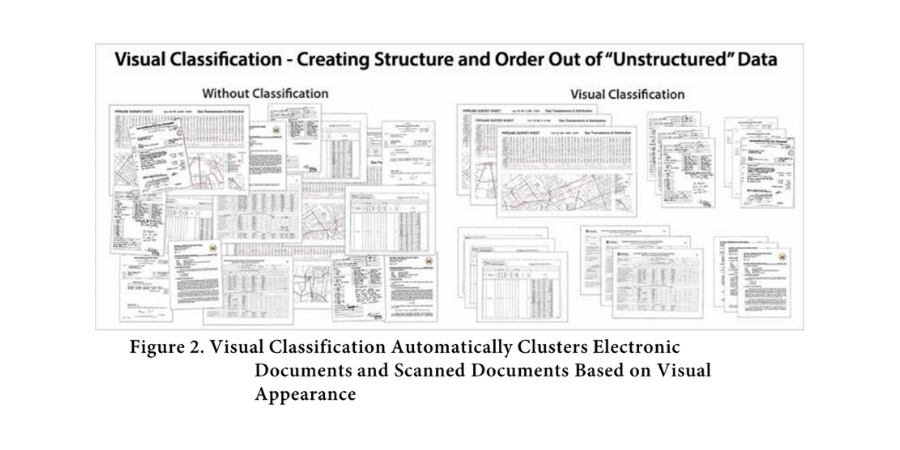
Visual Classification further transcends other processes by being the only technology equally adept at classifying scanned paper records as classifying native electronic files. Its ability to cluster, classify and review documents significantly reduces time and cost, while it generates more efficient and thorough review and analysis.
Visual Classification Technology: Automatically (means that there are no upfront rules to write, no exemplars to select) groups or clusters visually-similar documents no matter what the file type is and is not dependent on the presence of text for classification. The process of creating visual clusters begins as soon as files have been collected.
Typically, the number of visually-similar clusters is less than one percent of the total number of documents, and the clusters can be viewed and identified starting with the largest clusters first.
Within a few days, the team can:
- Review clusters representing well over 99% of all the documents,
- Eliminate clusters that do not have any relevance,
- Tag those remaining clusters that contain relevant document types,
- Assign document-type name labels to them, and
- Extract targeted information by
Zonal Attribute Extraction: The client can designate which data elements to extract from each document type, using a graphical user interface to simply click and drag extraction boxes on a document image from each cluster. Users can use delimiters to specify which data to extract and have filters to specify the format to use for extracted values. The system will then be automated to extract those data elements as more data is ingested, machine learning.
- Zonal Redaction: Enables clients to achieve appropriate, accurate and accelerated redaction for privacy and privilege requirements. Visual classification delivers precision redactions far exceeding traditional approaches.
- By grouping documents based on visual similarity the process enables reviewers to learn where the PII, trade secret, privilege, etc. is contained in different document types which greatly speeds review and makes redactions far more consistent.
For many years the most effective way to deal with large volumes of documents was text, so we used it and got pretty good at it despite the limitations of a text-dependent approach. However, using something because it was at one time expedient is no reason to continue when there is a more comprehensive and consistent approach with visual classification.
Needless to say, Verity Group is excited to provide these new capabilities to our clients.
To schedule a time to discuss how Visual Classification Technology will benefit your organization, please contact:
Jeffrey J. Witt: jwitt@verityinc.com
Direct: 312-754-1001